N30 專業實習 編號ZV3
3.1 研究流程概述
本研究的整體流程如圖 1 所示,主要包含五個階段:(1) 財報資料蒐集;(2) 文本前處理;(3) 三元素標註資料建構;
(4) 模型訓練;(5) 模型評估與誤差分析。

3.2 資料來源與蒐集方式本研究的資料來源主要包含以下三類:
(1)公開資訊觀測站(MOPS)本研究蒐集 2020 至 2024 年間上市公司年度報告與股東會年報摘要,特別聚焦於「管理層討論與分析(MD&A)」與「營運概況」章節,因其多以主觀語氣敘述營運成果與展望。
(2)產業涵蓋範圍為避免資料偏向單一產業,本研究選取電子、金融、製造、傳產與服務業之公司,確保語料具多樣性與跨產業性。
(3)資料清理流程蒐集後進行多輪清理,包括:1.移除無文字內容(如表格、編號、附錄)2.排除過短(少於 6 字)或過長(超過 50 字)的句子3.去除重複句或明顯無情緒資訊的句子4.最終共整理出約 1,000 句可用財報文本 作為本研究初始語料。
3.3 資料前處理與人工標註
(1)AI 句子擷取與前處理
由於財報文本內容龐大,
本研究採用 AI 工具協助句子擷取,包括:
1.自動句子斷詞與分段
2.關鍵詞比對(如成長、下降、回升、挑戰等)
3.初步判斷是否涉及財務表現或市場資訊
接著由研究成員逐句審核,排除以下句型:
1.與營運無關(如公司沿革、社會責任口號等)
2.文意不完整
3.重複或無法辨識情緒方向
此流程能提升後續標註品質,兼具效率與可控性。
(2)標註架構設計(Aspect, Opinion, Category)
本研究參考 SemEval-2016 Task 5 架構,
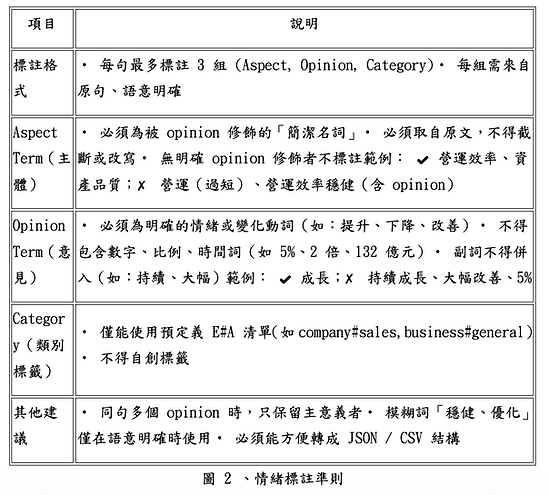
並依照財報特性制定「情緒標註準則 」
。如圖 2 所示。
(3)標註規則摘要
以下為本研究制定的核心規則:
1.Aspect 必須是被 opinion 修飾、語意完整的名詞。
2.不可截用不完整詞,
如「營運」若語意過泛則不標。
3.Opinion 限定為語意明確的動詞或形容詞。
4.不含副詞、時間字或數值,如「持續提升 5%」→ 標註為「提升」。
5.Category 必須從固定名單選取,不得自創。
同一句可標註多組,若多重情緒彼此衝突,保留主要意義者。
(4)人工審查
1.Aspect 與 Opinion 不對應
2.Category 使用錯誤
3.意見詞過度冗長
4.標註不一致